

特斯拉Dojo超算细节大公开:涉及指令集结构、数据格式等
特斯拉备受关注的Dojo超算指令集结构细节史上首次大公开!而且还大秀了一把Dojo的数据格式、系统网络,以及软件系统绕行死节点的能力。关于特斯拉自研的AI芯片D1,更多细节也被披露。

一切来自刚刚举办的硅谷芯片技术研讨会HOT CHIPS,听特斯拉硬件工程师Emil Talpes怎么说。
特斯拉Dojo超算
所谓Dojo,是特斯拉自研的超级计算机,能够利用海量的视频数据,做“无人监管”的标注和训练。
它有高度可扩展且完全灵活的分布式系统,能够训练神经网络,还能适应新的算法和应用。

不仅如此,还能从头开始构建大系统,而不是从现有的小系统演变而来。
每个Dojo ExaPod集成了120个训练模块,内置3000个D1芯片,拥有超过100万个训练节点,算力达到1.1EFLOP*(每秒千万亿次浮点运算)。
微架构方面,每个Dojo节点都有一个内核,是一台具有CPU专用内存和 I/O接口的成熟计算机。
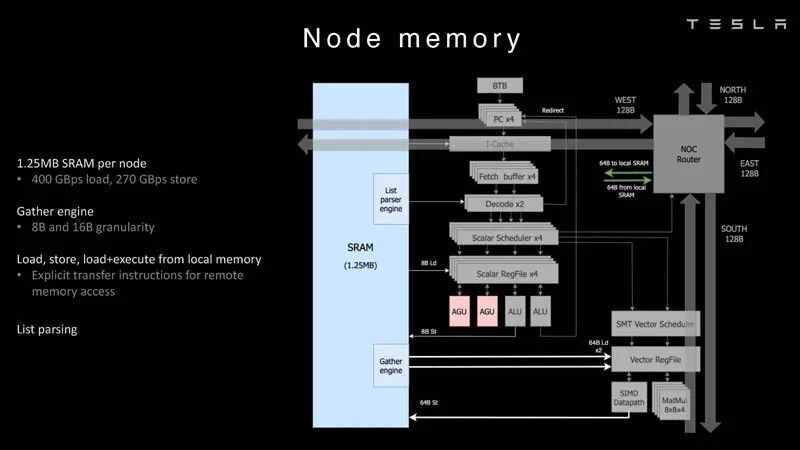
这很重要,因为每个内核都可以做到独立处理,而不依赖于共享缓存或寄存器文件。
每个内核拥有一个1.25MB的SRAM,这是主存储器。这种SRAM能以400GB/秒的速度加载,并以270GB/秒的速度存储。
芯片有明确的指令,可以将数据移入或移出Dojo超算中其他内核的外部SRAM存储器。

嵌入SRAM中的是列表解析器引擎(list parser engine),诸如此类的引擎可以将信息一起发送到其他节点或从其他节点获取信息,无需像其他CPU架构一样。
至于通信接口,每个节点都与2D网格相连,在节点边界处每周期有八个数据包。而且每个节点都有独立的网络连接,能与相邻节点进行无缝连接。
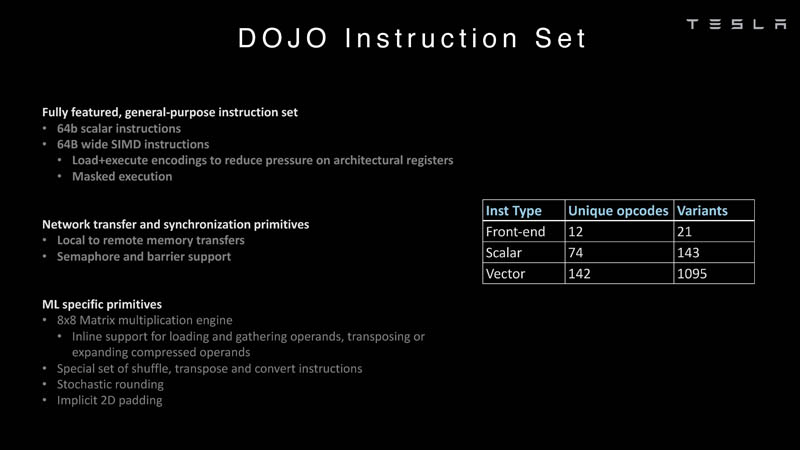
关于Dojo的指令集,它支持64位标量指令和64B SIMD指令,能够处理从本地到远程内存传输数据的原语(primitives),并支持信号量(semaphore)和屏障约束( barrier constraints)。
特斯拉自研AI芯片新进展
数据格式对AI来说至关重要,特别是芯片所支持的数据格式。
特斯拉借助Dojo超算来研究业界常见的芯片,例如FP32、FP16和BFP16。
FP32格式比AI训练应用的许多部分所需的精度和范围更广,IEEE指定的FP16格式没有覆盖神经网络中的所有处理层。
相反,GoogleBrain团队创建的Bfloat格式应用范围更广,但精度更低。
特斯拉不仅提出了用于较低精度和更高矢量处理的8位FP8格式,还提出了一组可配置的8位和16位格式,Dojo超算可以在尾数的精度附近滑动,以涵盖更广泛的范围和精度。
在给定时间内,特斯拉最多可以使用16种不同的矢量格式,但每个64B数据包必须属于同一类型。

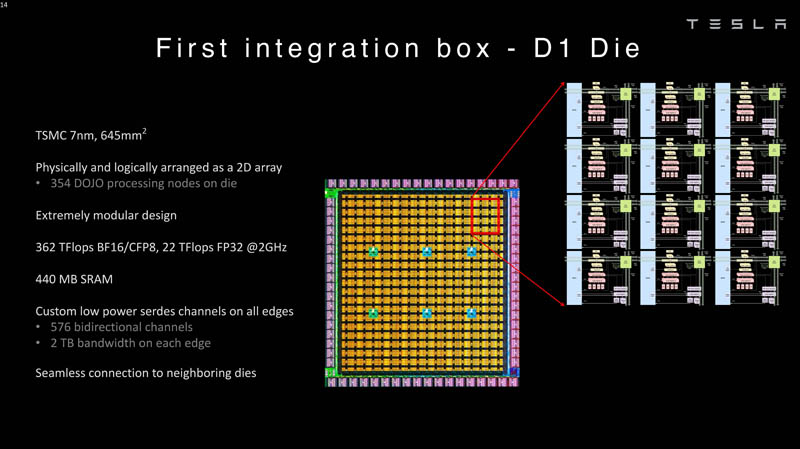
特斯拉自研的D1芯片,是Dojo ExaPod的核心。
由台积电制造,采用7纳米制造工艺,拥有500亿个晶体管,芯片面积为645mm²,小于英伟达的A100(826 mm²)和AMD Arcturus(750 mm²)。
每个芯片有354个Dojo处理节点和440MB的静态随机存储器。
D1芯片测试完成后,随即被封装到5×5的Dojo训练瓦片(Tile)上。
这些瓦片每边有4.5TB/s的带宽,每个模组还有15kW的散热能力的封盖,减掉给40个I/O的散热,也就是说每个芯片的散热能力接近600W。
瓦片也包含了所有的液冷散热和机械封装,这和Cerebras公司推出的WES-2芯片的封装理念类似。

演讲最后结束时,特斯拉工程师Emil Talpes表达了如下观点:
我们最终的目标是追求可扩展性。我们已经不再强调CPU中常见的几种机制,像是一致性、虚拟内存、全局查找目录。只因为当我们扩展到非常大的系统时,这些机制并不能很好地随之扩展。
相反,在整个网格中我们依靠的是那种快速、分散的SRAM存储,这样能够得到更高数量级的互连速度支持。




